Latest frontier flagship per lab · Chinese labs + NVIDIA · Excludes OpenAI, Anthropic, Google Gemini. Numbers are vendor-reported from official READMEs/blogs unless marked as independent eval.
| Model | Access | Input (cache miss) | Output | Cached input | Notes |
|---|---|---|---|---|---|
| MiniMax M3 | API | $0.30 | $1.20 | $0.06 | ≤512k ctx · 50% launch promo (list $0.60 / $2.40) |
| DeepSeek V4-Pro Max | Open + API | $0.435 | $0.87 | $0.003625 | MIT weights · 1M ctx |
| Kimi K2.6 | Open + API | $0.95 | $4.00 | $0.16 | Mod. MIT · 256k ctx · thinking default · K2.7-Code (code) pricing TBD |
| GLM-5.2 | Open + API | $1.40 | $4.40 | $0.26 | Official GLM-5.2 pricing · cached input storage limited-time free |
| Qwen3.7-Max | API only | $2.50 | $7.50 | $0.25 | Text agent · 1M ctx · Alibaba Model Studio |
| Qwen3.7-Plus | API only | $0.40 | $1.60 | - | Multimodal · ≤256k tier · $1.20 / $4.80 above 256k |
| MiMo-V2.5-Pro | Open + API | $1.00 | $3.00 | $0.20 | MIT weights · ≤256k tier · overseas API |
| Step 3.7 Flash | Open + API | $0.20 | $1.15 | $0.04 | Apache 2.0 · 256k ctx |
| Nemotron 3 Ultra | Open weights | - | - | - | OpenMDW-1.1 · self-host or NVIDIA NIM · 550B/55B MoE |
Pricing cross-checked 2026-06-01 · Qwen3.7-Plus added · Long-context tiers cost more · Plus not on OpenRouter yet
| Benchmark | M3 | DS V4-Pro | K2.6 | GLM-5.2 | Q3.7-Max | Q3.7-Plus | MiMo-V2.5 | Step-3.7 | Nemotron |
|---|---|---|---|---|---|---|---|---|---|
| AA Intelligence Index v4.0 ● | 55 | 52 | 54 (K2.6) | - | 57 | - | 54 | - | 47.7 |
| Vals Index ● | - | 56.23% | 55.55% (K2.6) | - | 57.29% | - | - | - | - |
| Arena Agent Net Improvement ● | - | - | - | 4.37% ±2.48 (#10) | - | - | - | - | - |
AA / Vals cross-checked 2026-06-17 · Arena Agent cross-checked 2026-06-17 from arena.ai/leaderboard/agent · Z.ai latest model pending on AA/Vals · Q3.7-Plus pending · Kimi column = K2.6 (K2.7-Code only on MCP Atlas) · Nemotron 3 Ultra AA II 47.7 (US open-weight ref, below the frontier)
| Benchmark | M3 | DS V4-Pro Max | K2.6 | GLM-5.2 | Q3.7-Max | Q3.7-Plus | MiMo-V2.5-Pro | Step-3.7 | Nemotron |
|---|---|---|---|---|---|---|---|---|---|
| Knowledge & Reasoning | |||||||||
| MMLU-Pro | - | 87.5 | - | - | 89.6 | 88.5 | 68.5 | - | 86.8 |
| GPQA Diamond | - | 90.1 | 90.5 (K2.6) | - | 92.4 | 90.3 | 66.7 | 78.41 | 87.0 |
| HLE (no tools) | - | 37.7 | 34.7 (K2.6) | 40.5 | 41.4 | 34.7 | - | 49.7 | 26.7 |
| HLE w/ tools | - | 48.2 | 54.0 (K2.6) | 54.7 | - | - | - | 48.1 | 37.4 |
| AIME 2026 | - | - | 96.4 (K2.6) | - | - | - | - | - | - |
| LiveCodeBench v6 | - | 93.5 | 89.6 (K2.6) | - | 91.6 | 89.6 | 39.6 | - | 89.0 |
| IMOAnswerBench | - | 89.8 | 86.0 (K2.6) | - | - | 86.0 | - | - | 88.6 |
| Apex Math Reasoning | - | 38.3 | - | - | 44.5 | 22.7 | - | - | - |
| Coding & Agentic | |||||||||
| SWE-bench Verified | - | 80.6 | 80.2 (K2.6) | - | 80.4 | 77.7 | 78.9 | 76.5 | 70.7 |
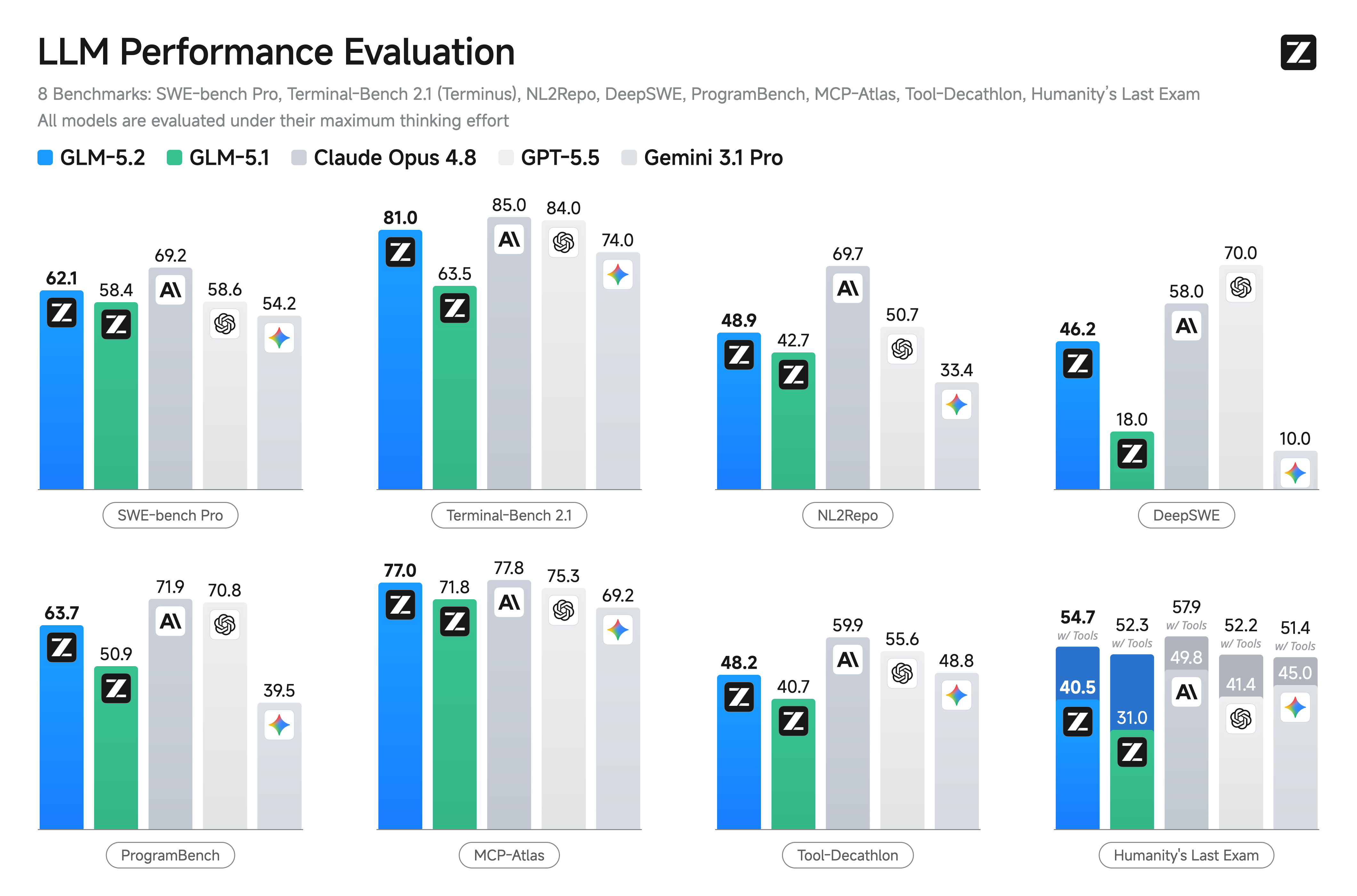
| SWE-bench Pro | 59.0 | 55.4 | 58.6 (K2.6) | 62.1 | 60.6 | 57.6 | 57.2 | 56.3 | - |
| SWE-bench Multilingual | - | 76.2 | 76.7 (K2.6) | - | 78.3 | 75.8 | - | 72.4 | 67.7 |
| Terminal-Bench 2.0 / 2.1 | 66.0 (2.1) | 67.9 (2.0) | 66.7 (2.0) (K2.6) | 81.0 (2.1) | 69.7 (2.0) | 70.3 (2.0) | 68.4 (2.0) | 59.6 (2.1) | 56.4 (2.1) |
| NL2Repo | - | - | - | 48.9 | - | 41.1 | - | - | - |
| DeepSWE | - | - | - | 46.2 | - | - | - | - | - |
| BrowseComp | - | 83.4 | 83.2 (K2.6) | - | - | - | - | 75.82 | 44.4 |
| Toolathlon | - | 51.8 | 50.0 (K2.6) | - | - | - | - | 49.5 | - |
| Tool-Decathlon | - | - | - | 48.2 | - | - | - | - | - |
| MCPAtlas Public | 74.2 | 73.6 | 76.0 (K2.7) | 77.0 | 76.4 | 73.2 | - | - | - |
| ClawEval Pass³ | - | - | 62.3 (K2.6) | - | 65.2 | 62.7 | 64.0 | 67.1 | - |
| ProgramBench | - | - | - | 63.7 | - | - | - | - | - |
| GDPval-AA (Elo) | - | 1554 | - | - | - | - | - | 1415.8 | - |
| τ²-Bench | - | - | - | - | - | - | - | - | - |
| Skillsbench | - | - | - | - | 59.2 | 54.9 | - | - | - |
| SciCode | - | - | 52.2 (K2.6) | - | 53.5 | 51.3 | - | - | 44.6 |
| CyberGym | - | - | - | - | - | - | - | - | - |
| KernelBench Hard | 28.8 | - | - | - | - | - | - | - | - |
| SWE-fficiency | 34.8 | - | - | - | - | - | - | - | - |
| FrontierSWE Dominance | - | - | - | 74.4% | - | - | - | - | - |
| PostTrainBench | 0.37 | - | - | 0.343 (34.3%) | - | - | - | - | - |
| SWE-Marathon | - | - | - | 13.0% | - | - | - | - | - |
| SimpleVQA Search | - | - | - | - | - | 81.7 | - | 79.16 | - |
| Long Context | |||||||||
| MRCR 1M | - | 83.5 | - | - | - | - | - | - | - |
| CorpusQA 1M | - | 62.0 | - | - | - | - | - | - | - |
GLM-5.2 official Z.ai docs cross-checked 2026-06-17 IST. Rows Z.ai has not republished for GLM-5.2 are left blank.
Official harness measuring pass rate on Next.js generation and migration workloads. Not comparable to SWE-bench-style vendor tables above. AGENTS.md column = extra passes when agents had bundled Next.js docs.
| Metric | M3 | DS V4-Pro | K2.6 | GLM-5.2 | Q3.7-Max | Q3.7-Plus | MiMo-V2.5 | Step-3.7 | Nemotron |
|---|---|---|---|---|---|---|---|---|---|
| Success rate ● | - | - | - | 75% | - | - | - | - | - |
| Success w/ AGENTS.md | 96% | - | - | - | - | - | - | - | - |
| Avg execution time | 181.30s | - | - | - | - | - | - | - | - |
| Harness (on eval) | - | - | - | OpenCode | - | - | - | - | - |
Only MiniMax M3 from this page matches our current matrix. Kimi K2.6, Qwen3.7, DeepSeek, MiMo, Step, and Z.ai latest are not listed yet; use Arena Agent below for current Z.ai independent agent metrics. Eval still shows Kimi K2.5 (21% / 135s) and MiniMax M2.7 (50% / 294s) on the same leaderboard.
LMArena via arena-ai-leaderboards snapshot 2026-06-02 (top 20 per board). API-only columns (Q3.7-Max, Q3.7-Plus) get LMArena / LiveBench where listed; Arena Agent supplies current GLM-5.2 agent metrics; OLLB row is open-weight only.
| Metric | M3 | DS V4-Pro | K2.6 | GLM-5.2 | Q3.7-Max | Q3.7-Plus | MiMo-V2.5 | Step-3.7 | Nemotron |
|---|---|---|---|---|---|---|---|---|---|
| LMArena Text Elo ● | - | - | - | - | 1475 | - | - | - | - |
| LMArena Code Elo ● | - | 1464 | 1518 (K2.6) | - | 1541 | - | 1471 | - | - |
| LiveBench global avg ● | - | 73.58 | 72.17 (K2.6) | - | 74.29 | - | - | - | - |
| LiveBench agentic coding ● | - | 56.67 | 58.33 (K2.6) | - | 51.67 | - | - | - | - |
| Arena Agent Net Improvement ● | - | - | - | 4.37% ±2.48 #10 · 9,429 sessions | - | - | - | - | - |
| Arena Agent Confirmed Success | - | - | - | 9.43% ±4.52 | - | - | - | - | - |
| Arena Agent Praise vs Complaint | - | - | - | 14.88% ±9.11 | - | - | - | - | - |
| Arena Agent Steerability | - | - | - | -6.00% ±4.50 | - | - | - | - | - |
| Arena Agent Bash Recovery | - | - | - | 1.69% ±3.28 | - | - | - | - | - |
| Arena Agent Tool Hallucination | - | - | - | 1.86% ±0.23 | - | - | - | - | - |
| Open LLM LB Average ● | TBD | - | - | - | - | - | - | - | - |
| EQ-Bench Creative Writing Elo ● | - | 1569.9 | 1781.6 (K2.6) | - | - | - | - | - | - |
LMArena arena IDs: Text qwen3.7-max-preview (1475);
Code qwen3.7-max-20260517 (1541), kimi-k2.6 (1518),
deepseek-v4-pro-thinking (1464), mimo-v2.5-pro (1471). Kimi / DeepSeek / MiMo not in Text top 20.
Arena Agent from arena.ai/leaderboard/agent: GLM 5.2 (Max), rank #10, MIT, SiliconFlow, 9,429 sessions.
LiveBench from livebench.ai (Jun 2026 crawl).
OLLB: none of the five submitted HF weights appear in open-llm-leaderboard/contents yet (checked parquet, 4576 entries).
EQ-Bench Elo from eqbench.com/creative_writing (Kimi-K2.6 and DeepSeek-V4-Pro entries only among current columns).
open-llm-leaderboard/contents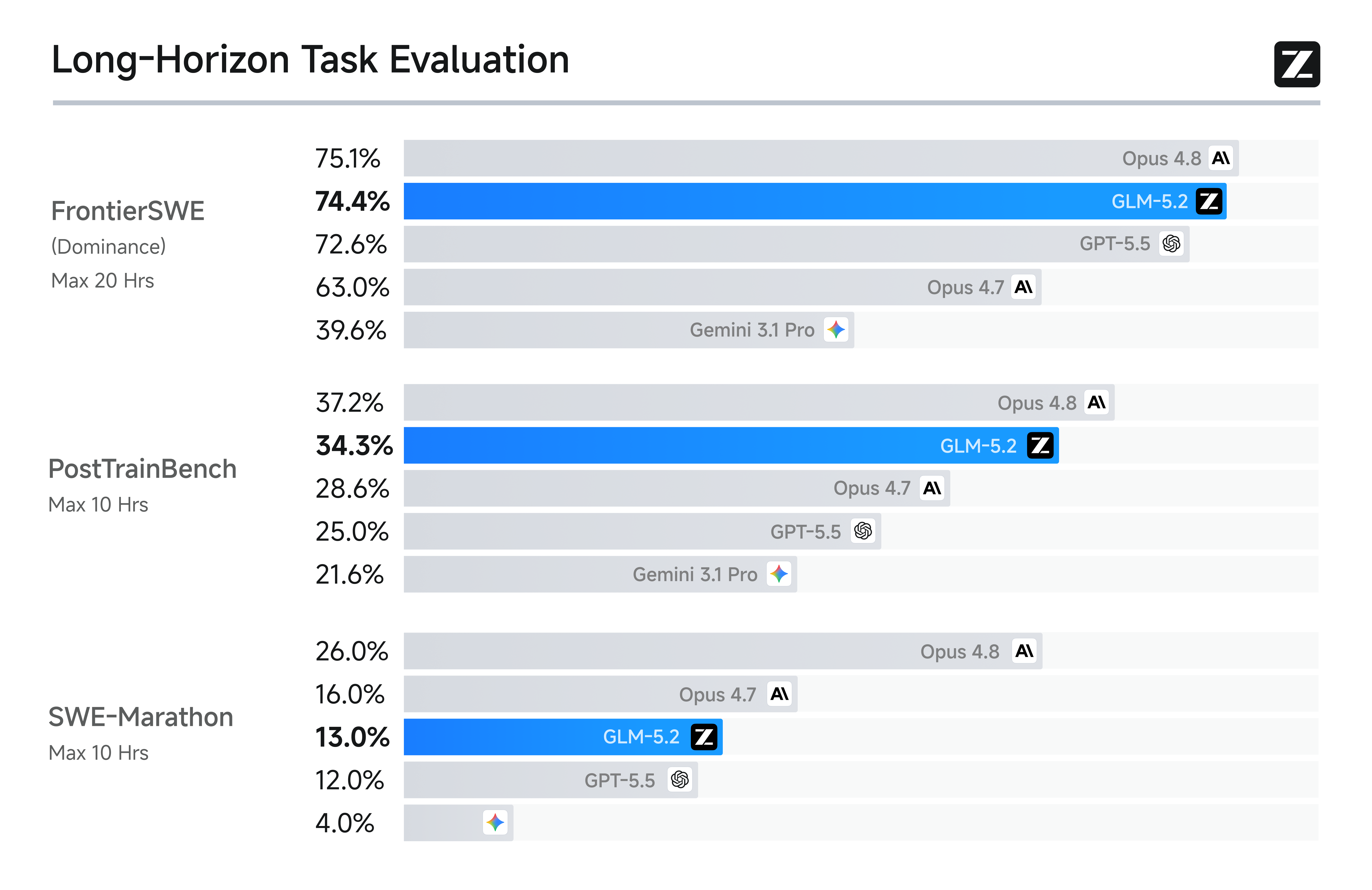{kind=link}
{kind=link}